本手册提供了 GPGPUSim 3.x 版本的文档。GPGPUSim 是一个周期精确的模拟器,聚焦 GPU 计算 (通用 GPU)。GPGPU-Sim 3.x 是最新的 GPGPUSim 版本。其包含了对 2.x 版本的诸多增强。
本手册主要分层 3 个部分。
- GPGPU-Sim 3.x 版本的微体系结构模型
- 一个 GPGPU-Sim 的使用章节,主要包括一下信息:
- 不同的仿真模式
- 设置选项(如何修改仿真体系结构的高层次参数)
- 仿真输出(微体系结构的统计数据)
- 当 GPGPU-Sim 性能仿真程序由于时间模型的错误出错或崩溃时的 debug 策略
- 一个解释 GPGPU-Sim 3.x 内部软件设计的章节。此章节的目标是为想要拓展模拟器以利于自身研究的使用者提供一个起点。
微结构模型
此章节描述了 GPGPU-Sim 3.x 建模的微结构模型。这个模型比 GPGPU-Sim 2.x 的时间模型更加详细。一些新的细节是通过检查 Nvidia 的专利得到的(这说明查看专利申请是逆向工程的好方法qaq)。这些细节包括建模取指令,记分牌,寄存器堆文件访存。3.x 的其他改进包括更详细的纹理缓存模型(基于预取纹理缓存结构)。此章节首先描述微体系结构的总体设计,紧接着描述各个组成部分,包括 SIMT core(硬件实现为 SM),簇(SM 簇),互连网络和内存分分区(常见于 L2,也就是 global memory)。
总览
GPGPU-Sim 3.x 运行由 CPU 部分和 GPU 部分组成的二进制代码文件。但是,GPGPU-Sim 中的微结构模型在 GPU 忙碌的时候报告周期,它没有建模 GPU 的时间或者 PCIe 的时间(也就是 GPU 和 CPU 间的内存转换)。有一些工作尝试结合 CPU 和 GPU 模拟器(由 GPGPUSim 建模),例如 fusionsim(链接已经挂了)。
精度
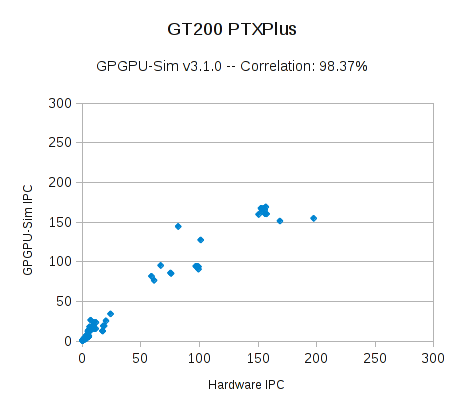
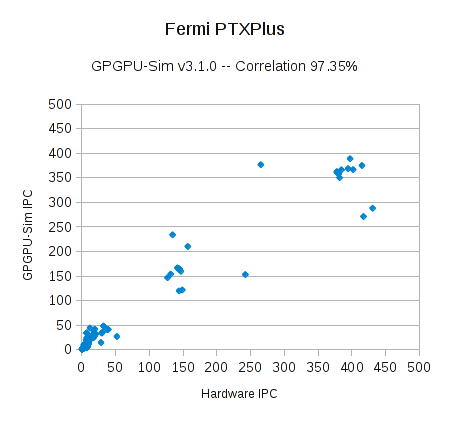
我们计算了模拟器 IPC 和真实硬件的相关性。当设置使用本地硬件指令集(PTXPlus,使用 -gpgpu_ptx_convert_to_ptxplus option 配置),GPGPU-Sim 3.1.0 在削减规模过后的 RODINIA 测试集(大约 260 个核函数)上获得了 98.3% 的相关性(图 1),97.3 % 的相关性(图 2)。我们的测试集包括了所有来自 [Che et. al. 2009] 论文中的基准测试集,以及 RODINIA 较晚版本的一些测试集。图中的每一个点代表一个核函数的发射。由于一些异常值,平均绝对误差为 35% 及 62%。
我们已经将用于计算这些相关性的电子表格包含在内,以演示如何计算这些相关系数。
顶层架构
GPGPU-Sim 支持 4 个独立的时钟域
- SIMT Core 簇(SM 簇)时钟域
- 互联网络时钟域
- L2 缓存时钟域,适用于所有的内存分割逻辑,除了 DRAM
- DRAM 时钟域
时钟频率可以是任何值 (相互之间无倍率要求)。也就是说,我们假设不同的时钟域之间存在同步器。
以下设计非常巧妙!
在 GPGPU-Sim 3.x 模型,相邻单元的时钟域通过交叉缓冲队列进行连接,其填充速率是源域的时钟频率,取出速率是目标域的时钟评论。
SIMT Core 簇
SIMT Cores 被分组成 SIMT Core 簇。同一个簇里的 SIMT Cores 共享一个互连网络的端口。
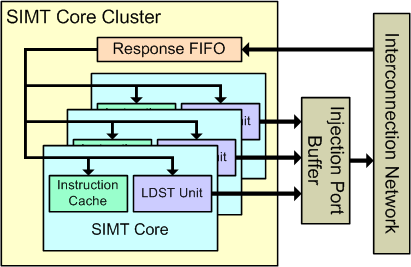
图 4
如上图所示,每个 SIMT Core Cluster 有一个单向传输的响应 FIFO(队列),存储从互连网络注入的包(数据,指令包)。这些包要么被导入一个 SIMT Core 的指令缓存 (如果它是服务于取指令未命中的内存相应),要被导入 SIMT Core 的内存流水线(LDST unit,访存单元)。数据包以 FIFO 的方式取出,如果 SIMT Core 无法接受 FIFO 头部的数据包,则响应 FIFO 将停止。对于 LDST 单元产生访存请求的情况,每个 SIMT Core 拥有自己的互连网络注入端口。但注入端口缓冲,是由簇内所有 SIMT Core 共享的。
注意 SIMT Core 相当于 SM,而不是 SM 的 subcore。GPGPU-Sim 3.x 版本不支持 subcore。
SIMT Cores
下图展示了 GPGPU-Sim 3.x 仿真的 SIMT Core 微结构。SIMT Core 是一个高度多线程化的流水线 SIMD (单指令多数据处理器),大概等价于 Nvidia GPU 中的 SM (流式多处理器) 或者 AMD GPU 中的 CU (计算单元)。SP (流处理器) 或者 CUDA 单元对应着 SIMD core 中 ALU 流水线的一条管道。
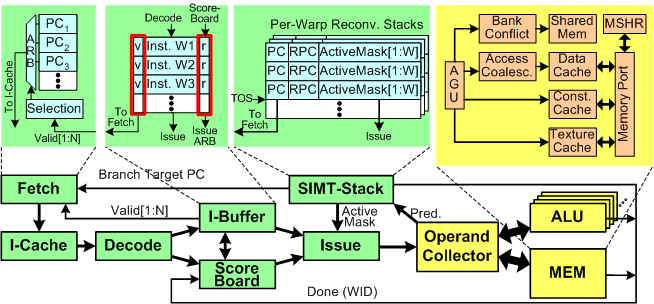
此微结构模型包含诸多 GPGPU-Sim 早期版本未发现的细节。主要的差异如下:
- 一个建模指令缓存并将 warp 调度(发射)阶段和新前端
- 记分牌逻辑,可以让一个 warp 的多条指令立即进入流水线
- 操作数收集器(operand collector)的详细模型,用于调度对单端口寄存器文件 bank 的操作数访问(用于减少寄存器文件的芯片面积和功耗)
- 支持多 SIMD 功能单元的灵活模型。这允许内存指令和 ALU 指令在不同的流水线中执行。
前端
如下所述,前端的主要阶段包括指令缓存访问和指令缓冲逻辑,记分板和调度逻辑,SIMT Stack。
取指令和译码
图 5 中的指令缓冲 (I-Buffer) 块用于缓冲指令,当这些指令从指令缓存中被取时。指令缓冲块被静态划分。所有在 SIMT Core 上运行的 warps 都有专用存储以放置指令。在当前的模型中,每个 warp 都有 2 个 I-Buffer 入口。这个 warp,每个 I-Buffer 入口有一个有效位,一个就绪位和一条解码的指令。入口的有效位指示着 I-Buffer 入口有一条未发射的指令。而就绪位指示着此 warp 的解码指令准备被发射到执行流水线。从概念上讲,就绪位在调度时和发射阶段通过记分牌和硬件资源的可用性进行设置(在模拟器软件中,执行准备就绪检查,而非实际设置一个就绪位)。初始状态下,I-Buffer 是空的,所有有效位和就绪位处于非激活状态。
如一个 warp 在 I-Buffer 中没有任何有效的指令,则有资格进行取指令操作。这些有资格的 warp 以轮转的调度方法获取指令缓存。一旦某条指令被选择,将发送一条读请求到指令缓存,使用当前调度 warp 的下一条地址。默认设置下,将取回两条连续的指令。一旦调度 warp 取指令,其 I-Buffer 的有效位将被激活,直到取回的指令发射到执行流水线。
指令缓存是一个只读的,无阻塞的组相连缓存,可以模拟 FIFO 和 LRU 替换策略,带有 on-miss 或者 on-fill 分配策略。对于指令缓存的请求将产生命中(hit),缺失(miss)和预定失败(reservation fail)三种情况。预定失败是指未命中状态保持寄存器(miss status hoding register, MSHR)已经装满,或者缓存组里已经没有可以替换的块,因为所有的块都被之前等待请求的预定占满了(请查看缓存这一节以获取更多细节)。在命中和缺失这两种情况下,轮转取指令调度器将移动到下一个 warp 进行处理。在命中的情况下,取回的指令将被送到译码阶段。在缺失的情况下,指令缓存将生成一个请求。当正在等待缺失的时候,此 warp 不会访问指令缓存。
当其所有的线程都完成执行,且没有未解决的存储或者等待写入本地寄存器的数据时,一个 warp 完成执行,且不再被取指令调度器考虑。当其所有的 warp 都完成执行,且没有等待中的操作时,一个线程块(thread block)完成执行。当其发出的所有线程块执行完毕,一个核函数(kernel)完成执行。
在译码阶段,最近取回的指令被译码和存储到到它们在 I-Buffer 中等待发射的对应的入口。
此阶段的模拟器软件设计在后面的取指令和解码软件模型设计中描述。
指令发射
第二个轮转仲裁器选择一个 warp 以从 I-Buffer 发射到流水线的剩余部分。此仲裁器和之前调度指令缓存访问的仲裁器解耦。此发射仲裁器可以设置为在每个周期从相同 warp 发射多个指令。当前检查的 warp 中的每个有效的指令 (也就是已经被解码且没有被发射) 由此个被发射,当 (1) 此 warp 没有在屏障(barrier)处等待,(2) 其在 I-Buffer 入口处有有效的指令,(3) 记分牌检查通过(请看记分牌这一节以获取更多细节),(4) 指令流水想的操作数获取阶段没有暂停。
访存指令(memory instruction,包括加载(load),存储(store), 内存屏障(memory barrier)将被发送到内存流水线。对于其他指令,它总是偏好 SP 流水线,如果此操作还能够被 SFU 流水线执行。但是,如果一个控制冒险(此外还有结构冒险,数据冒险)被检测到,那么此 warp 在 I-Buffer 中对应的指令将被冲刷掉。此 warp 的下一个 PC 更新为更新为下一条指令的地址 (假设所有的分支都不取)。对于更多关于处理控制流的信息,参考 SIMT Stack。
在发射阶段,屏障指令被执行。同时,SIMT 栈被更新(查看 SIMT 栈部分以获取更多细节),寄存器依赖被追踪(查看记分牌部分(就在下面)以获取更多细节)。warp 在发射阶段等待屏障 (CUDA 编程中的 __syncthreads() 指令)。
SIMT 栈
每个 warp 有一个 SIMT 栈,以处理单指令执行时的分支分离和多线程结构。因为分离减少了这些结构的效率,可以采用不同的技术来降低这种影响。一种最简单的技巧是基于后支配者堆栈的重汇聚机制。这一技巧在最早能够重新汇聚的地方同步了分离的分支,以增加 SIMT 结构的效率。和之前的版本一样,GPGPU-Sim 3.x 版本采用了这一机制。
SIMT 栈的条目(entry)代表了不同的分离水平。在每个分离的分支中,一个新的条目被压入栈顶。当此 warp 到达重新汇聚的点时,弹出栈顶部的条目。每个条目存储新分支的目标 PC,直接后支配者重汇聚 PC 以及向这个分支分离的线程的活跃掩码。在我们的模型中,每个 warp 的 SIMT 栈在这个 warp 的每条指令发射之后更新。目标 PC,在不分离的情况下,正常地被更新为下一个 PC。但是,在分离的情况下,有着新目标 PC,分离线程的对应掩码以及它们的立即后支持者的新的条目被压入栈中。因此,如果 SIMT 栈顶端入口的下一个PC不等于当前被检查指令的 PC,则检测到控制冒险。
详见 Dynamic Warp Formation: Efficient MIMD Control Flow on SIMD Graphics Hardware (http://doi.acm.org/10.1145/1543753.1543756) 以获取更多细节。
注意这里引入了编译中 SSA 的相关概念,需要复习一下。
注意,我们知道 NVIDIA 和 AMD 实际上是使用特殊的指令修改了它们的分离堆栈的内容。这些分离堆栈指令在 PTX 中没有暴露,但在实际硬件 SASS 指令集(可见使用 decuda 或 NVIDIA 的 cuobjdump)中可见。当 GPGPU-Sim 3.x 的当前版本被配置为通过 PTXPlus(见 PTX vs . PTXPlus 部分)执行 SASS 时,它忽略了这些低级指令,而是创建了一个可比较的控制流图(Control Flow Graph, CFG,编译优化中很常用)来识别即时的后控制者。我们计划在 GPGPU-Sim 3.x 的未来版本中支持低级分支指令的执行。
记分牌
记分牌算法检查 WAW 和 RAW 数据依赖冒险。如前面所述,warp 写入的寄存器在指令发射阶段被保留。记分牌算法通过 warp ID 进行索引。它将所需的寄存器编号存储在一个 warp ID 对应的条目中。被保留的寄存器将在回写阶段释放。
如前面所述,直到记分牌表明没有 WAW 和 RAW 数据冒险时,warp 中已解码的指令才能被调度发射。记分牌通过追踪已经发射但未回写的指令写了哪些寄存器来追踪 WAW 和 RAW 数据依赖冒险。
寄存器访问和操作数收集器
NVIDIA 的各种专利描述了一种被称为”操作数收集器 (operand collector)“的结构。操作数收集器是一组缓冲器和仲裁逻辑, 用单端口的 RAM 的多 bank 外观。整体布局节省了功耗和芯片面积,对提高吞吐量有重要意义。注意,AMD 也使用 banked 寄存器文件,但编译器负责确保这些文件被访问而不会发生 bank 冲突。
这里的 bank 不太好翻译,翻译存储银行有点怪,其实就是一个分块结构,翻译成存储体可能会好一点。
图 6 给出了GPGPU - Sim 3.x 对操作数采集器建模的详细方式。
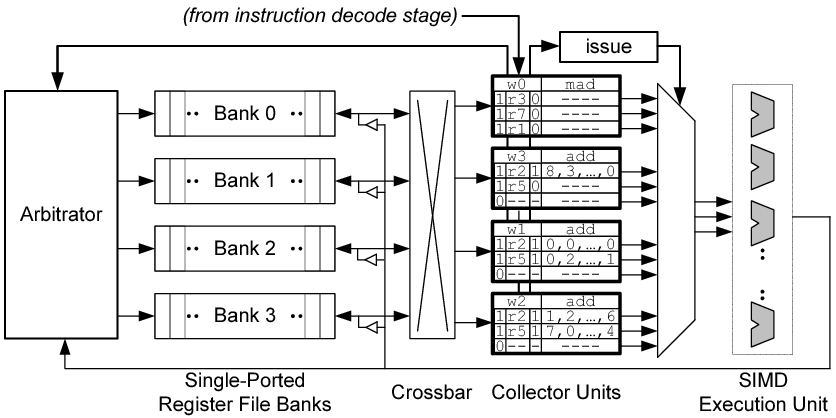
收集单元(collector units)并不用于通过寄存器重命名来消除名字依赖,而是用于在时间上分散寄存器操作数的访问,以确保在单个周期内不会对同一个寄存器存储体(bank)进行多次访问。在图示的组织结构中,每个收集单元包含三个操作数条目(operand entries)。每个操作数条目包含 4 个字段:一个有效位(valid bit)、一个寄存器标识符(register identifier)、一个就绪位(ready bit)以及操作数数据(operand data)。每个操作数数据字段可以容纳一个 128 字节的源操作数,该操作数由 32 个 4 字节元素组成(每个标量线程一个 4 字节值,适用于一个 warp)。此外,收集单元包含一个标识符,用于指示该指令所属的 warp。仲裁器(arbitrator)为每个寄存器库维护一个读取请求队列(read request queue),用于存放访问请求,直到它们被授予访问权限。
当从解码阶段获取到一条指令,且此时有一个空闲的收集单元,这个单元将被分配到这条指令,同时操作数,warp,寄存器标识符及有效字段将被填充。此外,源操作数读取请求在仲裁器中排队。为了简化设计,执行单元回写的数据始终优先于读取请求。仲裁器选择一组最多 4 个非冲突访问请求并发送到寄存器文件。此选择是为了减少 crossbar(互连)和收集器单元的面积,使得每个收集器单元每个周期仅接收一个操作数。
当每个操作数从寄存器文件中读取并放入相应的收集器单元中,设置了一个“就绪位”。最后,当所有操作数准备就绪时,指令将发给 SIMD 执行单元。
在我们的模型中,每个后端管道(SP,SFU,MEM)都有一组专用的收集器单元,并且它们共享一组通用收集器单元。每个管道可用的单元数量以及通用单元池的容量是可配置的。
ALU 流水线
GPGPU-Sim 有两种 ALU 功能单元
- SP 单元,执行所有类型的 ALU 指令除了超越函数运算。
- SFU 单元,执行超越函数运算指令(Sine, Cosine, Log 等)。
两种类型的单元都实现了流水线化和 SIMD 化。SP 单元每个周期通常执行一条 warp 指令,而 SFU 单元通常要好几个周期才能执行一条 warp 指令,这取决于指令的类型。例如,SFU 单元每 4 个周期可以执行一条 Sine 指令,每 2 个周期执行一个倒数指令 ()。
不同类型指令的执行延迟通常也不同。
每个 SIMT 核有一个 SP 单元和一个 SFU 单元。每个单元有一个独立的操作数收集器的发射接收端口 (由于接收操作数收集器的数据)。两个单元共享相同的连接回写阶段的输出流水线寄存器。操作数收集器的输出中,有一个结果总线分配器,以确保不会由于共享回写而导致这些单元陷入暂停。在发射到对应的功能单元之前,需要为每条指令在结果总线中分配一个周期槽。需要注意的是,内存流水线有其独立的回写阶段,并且不受此结果总线分配器的管理。
软件设计部分包含模型的更多实现细节。
内存流水线
GPGPU-Sim 支持 CUDA 中的各种内存空间,这些空间在 PTX 中可见。在我们的模型中,每个 SIMT 核心都有 4 种不同的片上一级内存:共享内存、数据缓存、常量缓存和纹理缓存。下表展示了每种片上内存服务的内存访问类型。
| Core Memory | PTX Accesses |
|---|---|
| Shared memory (R/W) | CUDA shared memory (OpenCL local memory) accesses only |
| Constant cache (Read Only) | Constant memory and parameter memory |
| Texture cache (Read Only) | Texture accesses only |
| Data cache (R/W - evict-on-write for global memory, writeback for local memory) | Global and Local memory accesses (Local memory = Private data in OpenCL) |
尽管这些内存空间在物理上被建模为独立的结构,但它们都是内存流水线(LDST单元)的组成部分,因此它们共享相同的写回阶段。以下描述了每个内存空间的服务方式:
- 纹理内存 (Texture Memory) - 对纹理内存的访问会被缓存到 L1 纹理缓存(仅用于纹理访问)中,也会被缓存到 L2 缓存(如果启用)。L1 纹理缓存是根据 1998 年论文中描述的特殊设计 ([3] (http://wwwgraphics.stanford.edu/papers/texture_prefetch/))。GPU 上的线程不能写入纹理内存,因此 L1 纹理缓存是只读的。
- 共享内存 (Shared Memory) - 每个 SIMT 核心包含一个可配置的共享内存区域,线程块中的线程可以共享该内存。此内存空间没有 L2 支持,并且由程序员显式管理。
- **常量内存 (Constant Memory) ** - 常量和参数内存被缓存到只读的常量缓存中。
- **参数内存 (Parameter Memory) ** - 与常量内存类似,由只读常量缓存服务。
- **本地内存 (Local Memory) ** - 本地内存会被缓存到 L1 数据缓存,并由 L2 缓存支持。与全局内存类似处理,但值会在逐出时写回,因为本地内存 (私有数据) 无法共享。
- 全局内存 (Global Memory) - 全局内存和本地内存的访问都通过 L1 数据缓存进行服务。来自同一 warp 的标量线程的访问会在半 warp 级别上进行合并,如 CUDA 3.1 编程指南中所述 ([4] (http://developer.nvidia.com/nvidia-gpucomputing-documentation))。这些访问的处理速率为每个 SIMT 核心周期 2 次,因此,一个完美合并的内存指令(每个半 warp 一次访问)可以在一个周期内得到服务。对于生成超过 2 次访问的指令,这些访问会以每周期 2 次的速率访问内存系统。例如,如果一条内存指令生成 32 次访问(每个 warp 的一个 lane 一次),它将至少需要 16 个 SIMT 核心周期才能将指令移到下一个流水线阶段。
下面的小节描述了第一层存储器结构。
L1 数据缓存
L1 缓存是用于本地和全局内存访问的私有的,每个 SIMT 核心的第一级缓存。L1 缓存没有划分 bank,能够为每个 SIMT Core 的两个聚合内存请求服务。到来的内存请求跨度不能超过 L1 数据缓存的两条缓存线(cache lin))。需要注意的是 L1 数据缓存并不是连贯的。
下表总结了 L1 数据缓存的写策略。
| Local Memory | Global Memory | |
|---|---|---|
| Write Hit | Write-back | Write-evict |
| Write Miss | Write no-allocate | Write no-allocate |
对于本地内存(Local Memory),L1数据缓存(L1 Data Cache)采用写回(Write-back)策略,并使用不分配写(Write No-Allocate)策略。对于全局内存(Global Memory),写命中(Write Hit)会导致缓存块被驱逐(Eviction)。这一策略模拟了 PTX ISA 规范中所定义的全局存储(Global Store)的默认策略 [5] (http://developer.nvidia.com/nvidia-gpucomputing-documentation)。
不分配写(Write No-Allocate)是一种缓存写策略,指的是当一个写操作未命中缓存 (Cache Miss)时,数据不会被加载到缓存,而是直接写入主存(或者更高级的缓存,如 L2/L3)。
这种策略的核心思想是,“写入数据不需要缓存,因为它可能不会被立即再次读取。”
对 L1 数据缓存命中的内存访问将在一个 SIMT 核心时钟周期内完成处理。未命中的访问请求会被插入到FIFO 未命中队列(FIFO miss queue)。L1 数据缓存每个 SIMT 核心时钟周期最多可以生成一个填充请求(fill request),前提是互连注入缓冲区(interconnection injection buffers)能够接受该请求。
缓存使用未命中状态保持寄存器(Miss Status Holding Registers,MSHR)来存储正在处理的未命中状态。这些寄存器被建模为全相联数组(fully-associative array)。如果在一个请求正在传输的同时发生了冗余的内存访问,这些访问将被合并到 MSHR 中,以避免重复请求相同的缓存块。MSHR 表具有固定数量的 MSHR 条目,每个 MSHR 条目可以为单个缓存行服务多个未命中请求。MSHR 的条目数量以及每个条目可服务的最大请求数是可配置的。
当缓存未命中时,该请求将被添加到 MSHR 表中。如果该缓存行没有正在进行的请求,则会生成一个填充请求 (fill request,和之前的访存请求不同!)。当填充请求的响应到达缓存时,该缓存行会被插入到缓存中,并且相应的 MSHR 条目将被标记为已填充 (filled)。对于已填充的 MSHR 条目,每个周期最多可以处理一个请求。当所有等待该 MSHR 条目的请求都被响应和处理完毕后,该 MSHR 条目将被释放。
纹理缓存 (Texture Cache)
纹理缓存模型是预取 (prefetching) 纹理缓存 (参考)。纹理内存访问通常表现出空间局部性 (spatial locality) ,研究发现,大约 16 KB 的存储即可有效捕获这种局部性 (参考)。在现实的图形使用场景下,许多纹理缓存访问会发生未命中 (cache miss)。从 DRAM 访问纹理数据的延迟通常在数百个时钟周期的量级。
由于存储访问延迟较长且缓存容量较小,缓存分配策略变得至关重要。预取纹理缓存通过在时间上解耦缓存标签(cache tags)和缓存数据块(cache blocks)的状态来解决这个问题。标签数组(tag array) 代表了缓存在数百个时钟周期后服务未命中请求后的状态,而数据数组(data array) 代表了未命中请求完成后缓存的实际状态。
关键机制在于使用重排序缓冲区(reorder buffer),确保返回的纹理未命中数据按照标签数组看到的访问顺序正确地放入数据数组。更多细节请参阅原始论文(参考)。
常量(只读)缓存(Constant (Read Only) Cache)
对常量内存(constant memory)和参数内存(parameter memory)的访问都会通过 L1 常量缓存(L1 constant cache)。该缓存采用标签数组(tag array),其工作方式与 L1 数据缓存类似,唯一的区别是它不能被写入(只读)。
线程块 / CTA / 工作组 (work group) 调度
上面三个概念其实是一种东西。线程块在 CUDA 术语中称为合作线程数组 (Cooperative Thread Arrays, CTAs),在 OpenCL 中称为工作组 (Work Group)。它们被一次性发射到 SIMT Cores 中。线程块发射机制在每个 SIMT Core 时钟周期以轮转方式选择和循环 SIMT Core 簇 (也就是 SM)。对于每个被选中的 SIMT Core 簇,将以轮转的方法选择和循环 SIMT Cores。对于每个选中的 SIMT 核,如果该 SIMT 上有足够的资源,则将从所选核函数 (kernel) 发出一个线程块。
如果应用使用了多个 CUDA 流或者命令队列,可以在 GPGPU-Sim 中同步执行多个核函数 (kernel)。不同的核函数可以在不同的 SIMT Core 上执行。单个 SIMT Core 一次只能从单个内核执行线程块。如果正在同步执行多个核函数,将同样以轮转的方式选择核函数向每个 SIMT Core 发射。
NVIDIA CUDA 编程指南中描述了 CUDA 体系结构上的同步核函数 (kernel) 执行。
互连网络
互连网络负责SIMT核心集群和内存分区单元之间的通信。为了模拟互连网络,我们将“booksim”模拟器与 GPGPU-Sim 接口。Booksim 是一个独立的网络模拟器,可以在此处找到。Booksim 能够模拟基于虚拟通道的 Tori 和 Fly 网络,并且具有高度的可配置性。它可以通过参考 Dally 和 Towles 的《Principles and Practices of Interconnection Networks》一书来最好地理解。我们将修改后的 booksim 版本称为 Intersim。Intersim 具有自己的时钟域。原始的 booksim 仅支持单一的互连网络。我们做了一些修改,使其能够模拟两个互连网络:一个用于从SIMT Core 簇(SM 簇,也可以说是 SM 组)到内存分区的流量,另一个用于从内存分区到 SIMT Core 簇(SM 簇)的流量。这是避免可能导致协议死锁的循环依赖的一种方式。另一种方式是在单一物理网络上为请求和响应流量分配专用虚拟通道,但当前版本的公开发布版未完全支持此功能。注意:Stanford 现已发布了 Booksim 的更新版本(Booksim 2.0),但 GPGPU-Sim 3.x 尚未使用它。请注意,SIMT Core 簇(SM 簇)之间并不直接通信,因此在互连网络中没有一致性流量的概念。只有四种数据包类型:(1)从 SIMT Core 簇(SM 簇)发送到内存分区的读请求和(2)写请求,以及(3)从内存分区发送到SIMT核心集群的读回复和(4)写确认。
集中特性
在 GPGPU-Sim 中,SIMT Core 簇(SM)充当外部集中器。从互连网络的角度来看,SIMT Core 簇(SM)是一个单独的节点,连接到该节点的路由器(router)只有一个注入端口和一个弹出端口。
与GPGPU-Sim的接口
无论其内部配置如何,互连网络都提供一个简单的接口,用于与连接到它的 SIMT Core 簇(SM)和内存分区进行通信。为了注入数据包,SIMT Core 簇(SM 簇)或内存控制器首先检查网络是否有足够的缓冲区空间来接受它们的数据包,然后将数据包发送到网络。对于弹出操作,它们会检查网络中是否有等待弹出的数据包,如果有,则将其弹出。这些操作发生在每个单元的时钟域中。数据包的序列化由网络接口内部处理,例如,SIMT Core 簇(SM 簇)在 SIMT Core 簇(SM 簇)的时钟域中注入数据包,但路由器每个互连时钟周期只接受一个 flit。更多实现细节可以在软件设计部分找到。
这里的 flit 意思是微片,但我还没有在代码中找到对应的实现。
内存分区
GPGPU-Sim 的内存系统由一组内存分区(memory partition)建模。如图 7 所示。每个内存分区包括一个 L2 bank,一个 DRAM 访存调度器和一个片外 DRAM 通道。原子操作的功能执行也发生在原子操作执行阶段的内存分区中。每个内存分区都分配了一个物理内存地址的子集。默认情况下,全局线性地址空间在按256个字节分块的分区之间交织在一起。地址空间的分区以及地址空间对 DRAM 行,每个分区中的 bank 和列的详细映射都是可配置的,并且在地址解码部分中进行了描述。
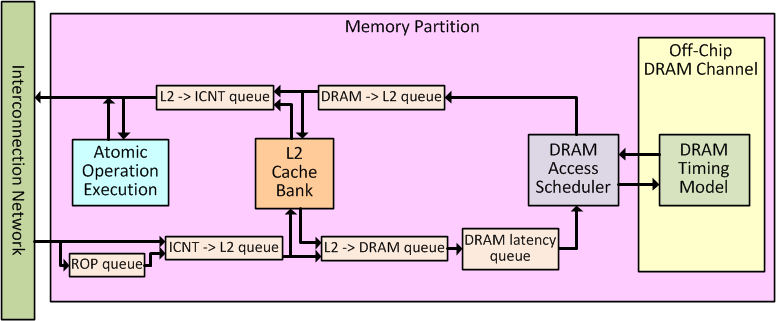
当 L2 缓存(启用时)可用于处理传入的纹理(Texture)请求,以及(在相应配置下)非纹理(Non-Texture)的内存请求。需要注意的是,在Quadro FX 5800(GT200)配置中,L2 缓存仅用于处理纹理引用。当发生**缓存未命中(Cache Miss)**时,L2 缓存存储体(Cache Bank)会向DRAM 通道(DRAM Channel)生成内存请求,这些请求将由离片式 GDDR3 DRAM(Off-Chip GDDR3 DRAM) 进行处理。
下列小节将更详细地描述数据流如何在内存分区(Memory Partition)中流动,以及前述各个组件的具体工作方式。
内存分区连接和交通流量
Figure 展示了单个内存分区(Memory Partition)内部的三个子组件,以及在它们之间传输内存请求和响应的多个 FIFO 队列。
内存请求包从互连(Interconnect)进入内存分区,并首先进入 ICNT->L2 队列。非纹理(Non-Texture)访问请求通过 Raster Operations Pipeline(ROP)队列处理,以模拟最小 460 个 L2 时钟周期的流水线延迟,这一延迟基于对 GT200 架构的微基准测试研究(http://www.stuffedcow.net/files/gpuarch-ispass2010.pdf)。L2 缓存存储体(L2 Cache Bank)每个 L2 时钟周期从 ICNT->L2 队列取出一个请求并进行处理。对于未命中 L2 缓存的请求,L2 会向 L2->DRAM 队列推送新的离片 DRAM(Off-Chip DRAM)请求。如果 L2 缓存被禁用,请求包会直接从 ICNT->L2 队列取出,并直接推入 L2->DRAM 队列,仍然遵循 L2 时钟频率。从离片 DRAM 返回的填充请求(Fill Requests)会从 DRAM->L2 队列取出,并由 L2 缓存存储体处理。L2 缓存对 SIMT 核心的读取响应(Read Replies)则被推入 L2->ICNT 队列,通过互连传输给 SIMT 核心。
DRAM latency 队列是一个固定延迟(Fixed Latency)队列,它用于建模 L2 访问和 DRAM 访问之间的最小延迟(即 L2 未命中后访问 DRAM 所需的最短延迟)。这一延迟基于微基准测试的观察,队列的作用是简单地模拟这种延迟(而不是复现引起该延迟的硬件机制)。从 L2->DRAM 队列输出的请求会在 DRAM latency 队列中停留固定数量的 SIMT 核心时钟周期,然后,每个 DRAM 时钟周期,DRAM 通道会从 DRAM latency 队列取出一个请求,并交由离片 DRAM 处理。每个 DRAM 时钟周期,处理完成的请求会被推入 DRAM->L2 队列。
需要注意的是,从互连进入内存分区(ROPor ICNT->L2 队列)的数据传输发生在 L2 时钟域,而从内存分区注入回互连(L2->ICNT 队列)的数据传输发生在互连(ICNT)时钟域。
L2 缓存模型和缓存层次结构
L2 缓存模型和位于 SIMT Core 中的 L1 数据缓存非常相似。可以查看之前的章节以获取更多细节。当启用缓存全局内存空间数据时,L2 充当带有如下表所示写入策略的读/写缓存。
| Local Memory | Global Memory | |
|---|---|---|
| Write Hit | Write-back for L1 write-backs | Write-evict |
| Write Miss | Write no-allocate | Write no-allocate |
另外,需要注意的是,L2 缓存是一个统一的末级缓存(last level cache),由所有 SIMT 核心共享,而 L1 缓存是每个 SIMT 核心私有的。
私有的 L1 数据缓存(L1 data caches)不是一致的(non-coherent)(其他 L1 缓存仅用于只读地址空间)。GPGPU-Sim 中的缓存层次结构是非包含性(non-inclusive)且非排他性(non-exclusive)的。此外,在缓存层次结构中,随着缓存级别的增加,缓存行大小不会减少(non-decreasing cache line size)。同时,来自一级缓存(L1)的内存请求不能跨越两个 L2 缓存行。这两个限制确保:
- 来自低级缓存的请求可以由高级缓存中的一个缓存行提供服务。这保证了 L1 缓存的请求可以被 L2 缓存原子地处理。
- 原子操作(Atomic Operations)在 L2 缓存中不需要访问多个缓存块。
这一限制简化了缓存设计,并防止在 L1 缓存请求非原子化处理时可能出现的活锁(Live-lock)问题。
原子操作执行阶段
原子操作执行阶段是一个非常理想化的原子指令执行模型。具有非冲突内存访问的原子指令在内存分区中合并为一个内存请求,并在一个周期内执行。在性能模型中,我们目前将原子操作建模为一个全局加载操作,跳过 L1 数据缓存。这在 SIMT Core 中生成所有必要的寄存器写回流量(以及数据危害停顿)。在 L2 缓存中,原子操作将已访问的缓存行标记为脏(将其状态更改为已修改),以生成写回到 DRAM 的流量。如果 L2 缓存未启用(或仅用于纹理访问),则原子操作不会生成DRAM写流量(这是一个非常理想化的模型)。
DRAM 调度和时序模型
timing model 最好翻译成时序模型,而不是时间模型。
GPGPU-Sim 模拟了 DRAM 调度和时序。GPGPU-Sim 实现了两种开放页模式的 DRAM 调度器:FIFO(先进先出)调度器和 FR-FCFS(先到先服务)调度器,下面将对其进行描述。这些可以通过配置选项 -gpgpu_dram_scheduler 进行选择。
FIFO 调度器
FIFO调度器按照接收到的顺序处理请求。这通常会导致大量的预充电和激活操作,因此会导致较差的性能,特别是对于那些生成大量内存流量的应用,这些应用相对于其执行的计算量来说,内存流量占比过大。
FR-FCFS
先行行先到先服务(FR-FCFS)调度器优先处理对当前打开行的请求。调度器将首先调度队列中所有指向已打开行的请求。如果没有这样的请求,调度器将为最旧的请求打开一个新行。此调度器的代码位于 dram_sched.h/.cc 文件中。
DRAM 时序模型
GPGPU-Sim 精确模拟了图形 DRAM 内存。目前,GPGPU-Sim 3.x 模拟的是 GDDR3 DRAM,尽管我们正在努力添加详细的 GDDR5。可以使用选项 -gpgpu_dram_timing_opt nbk:tCCD:tRRD:tRCD:tRAS:tRP:tRC:CL:WL:tCDLR:tWR 设置以下 DRAM 时序参数。目前,我们没有模拟DRAM刷新操作的时序。有关每个参数的更多细节,请参见 GDDR3 规格(http://www.hynix.com/datasheet/pdf/dram/HY5RS123235FP(Rev1.3).pdf)。
nbk:内存银行数量 number of banks
tCCD:列到列延迟(不同银行的RD/WR到RD/WR)Column to Column Delay (RD/WR to RD/WR different banks)
tRRD:行到行延迟(不同银行的激活到激活)Row to Row Delay (Active to Active different banks)
tRCD:行到列延迟(激活到RD/WR/RTR/WTR/LTR)Row to Column Delay (Active to RD/WR/RTR/WTR/LTR)
tRAS:激活到预充电命令周期 Active to PRECHARGE command period
tRP:预充电命令周期 PRECHARGE command period
tRC:激活到激活命令周期(同一银行)Active to Active command period (same bank)
CL:CAS延迟 CAS Latency WRITE latency
WL:写延迟 WRITE latency
tCDLR:最后数据输入到读取延迟(从写操作到读操作的切换)Last data-in to Read Delay (switching from write to read)
tWR:写恢复时间 WRITE recovery time
这一块是 DRAM 相关的知识,我不是特别了解,就只是按字面意思翻译了一下
在我们的模型中,每个内存 bank(内存银行,存储体)的命令按轮转方式调度。bank 按圆形数组排列,并有一个指针指向优先级最高的 bank。调度器按顺序遍历 bank 并发出命令。每当为某个 bank 发出激活或预充电命令时,优先级指针将指向下一个bank,确保其他 bank 的待处理命令最终会被调度。
指令集体系结构(ISA)
PTX和SASS
GPGPU-Sim 模拟 NVIDIA使用的 Parallel Thread eXecution(PTX)指令集。PTX 是一个伪汇编指令集;即它不能直接在硬件上执行。ptxas 是 NVIDIA 发布的汇编器,用于将 PTX 汇编成硬件运行的本地指令集 SASS。每一代硬件支持不同版本的 SASS。因此,PTX 在编译时会被编译成多个对应不同硬件代的 SASS 版本。尽管如此,PTX 代码仍然被嵌入到二进制文件中,以支持未来的硬件。在运行时,运行时系统会根据可用硬件选择适当 的SASS 版本。如果没有匹配的版本,运行时系统会调用嵌入 PTX 的即时编译器(JIT),将其编译成对应硬件的 SASS。
PTXPlus
GPGPU-Sim 能够运行 PTX。然而,由于PTX 不是实际在硬件上运行的代码,它的准确性是有限的。主要原因是编译器的过程,如强度归约、指令调度、寄存器分配等。
为了在 GPGPU-Sim中 运行 SASS 代码,需要添加新功能:
- 新的寻址模式
- 更复杂的条件码和谓词
- 额外的指令
- 额外的数据类型
为了避免开发和维护两个解析器和两个功能执行引擎(一个用于 PTX,另一个用于 SASS),我们选择扩展 PTX,加入所需的功能,以提供与 SASS 一一对应的映射。PTX 及其扩展被称为 PTXPlus。为了运行 SASS,我们执行一个语法转换,将 SASS 转换为 PTXPlus。
PTXPlus 的语法与 PTX 非常相似,只是在此基础上添加了新的寻址模式、更复杂的条件码和谓词、额外的指令和更多的数据类型。需要注意的是,PTXPlus 是 PTX 的超集,这意味着有效的 PTX 也是有效的PTXPlus。有关 PTX 和 PTXPlus 之间具体差异的更多细节,请参见 PTX vs. PTXPlus。
从SASS到PTXPlus
当配置文件指示 GPGPU-Sim 运行 SASS 时,使用一个转换工具 cuobjdump_to_ptxplus,将二进制文件中嵌入的 SASS 转换为 PTXPlus。有关转换过程的完整细节,请参见 GPGPU-Sim 使用部分的 PTXPlus Conversion。然后,使用 PTXPlus 进行仿真。当 SASS 转换为 PTXPlus 时,只有语法发生变化,指令及其顺序与 SASS 完全一致。因此,编译器优化应用于本地代码的效果得以完全保留。目前,GPGPU-Sim 仅支持将 GT200 SASS 转换为 PTXPlus。
GPGPU-SIM 的软件设计
取指令和解码软件模型
PTX vs. PTXPlus

