GPU基础知识
CUDA 的编程模型概述
当通过 CUDA 编译时,GPU 可以被视为极高数量并行线程的计算设备。
目前主流的英伟达 GPU 模拟器都是基于 CUDA 编程模型的。
GPU 线程调度与 CUDA 编程模型
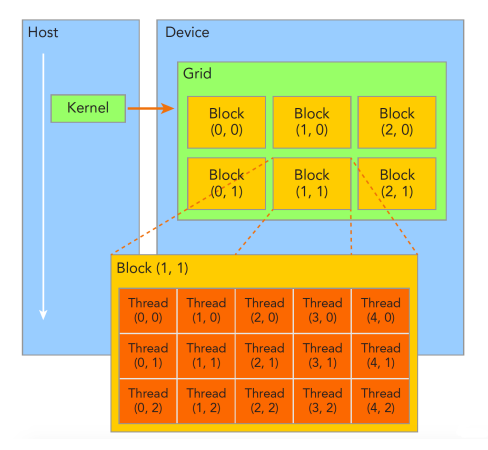
GPU 本质上是 CPU 的一个协处理器,用于多线程执行大量相同指令。GPU 所运算的指令及数据一般由 CPU 进行分配,而英伟达架构 GPU 采用 CUDA 编程模型实现应用程序到 GPU 硬件的联系。CUDA 应用程序一般由多个 Kernel 组成,每个 Kernel 由大量线程并行执行,以执行特定的计算任务。Kernel 中的线程被分层次组织为网格(Grid)、线程块(Block)以及线程(Thread)。如图 1,每个 Kernel 的被分成多个线程块,每个线程块又包含大量线程,这些线程执行相同代码,但处理不同的数据。
GPU 中,每个 CUDA Core 同一时刻只能执行一个线程,然而 GPU 需要处理大量指令相同的线程,在线程层面调度是低效的。在 CUDA 模型的线程块中,一定数量(如 32 个)线程组成一个线程束(warp),同一个线程束中的所有线程同一时刻只会执行同一条指令,因而线程束为 GPU 执行的最小调度单位。当 Kernel 执行时,调度程序将线程块分配给不同的流多处理器,一个线程块中的所有线程束会在一流多处理器上执行,而单个流多处理器可以同时执行多个线程块。不同的线程调度方式对 CUDA 应用程序的性能有显著影响。
线程块 Block
一个线程块是一个线程的批处理,它通过一些快速的共享内存有效地分享数据并且在制定的内存访问中同步它们的执行。更准确地说,它可以在 Kernel 中指定同步点,一个块里的线程被挂起直到它们所有都到达同步点(采用同步机制)。
每个线程由它的线程 ID 所确定,ID 是块内的线程编号。根据线程的ID 可以进行复杂寻址,一个应用程序可以指定一个块作为一个二维或三维数组的任意大小,并且通过一个 2- 或 3- 组件索引代替来指定每条线程。对于一个大小为 (Dx,Dy)二维块,线程的索引是(x, y),这个线程 ID 是(x + y Dx)。而对于一个三维的大小为 (Dx,Dy,Dz)的块,这个线程的索引是(x,y,z),线程的 ID 是(x + y Dx + z DxDy)。
线程束 warp
线程块在一个批处理中被一个多处理器执行,被称作 active。每个active 块被划分成为 SIMD 线程组,称为 warps; 每一条这样的 warp 包含数量相同的线程,叫做 warp 大小,并且在 SIMD 方式下通过多处理器执行; 线程调度程序周期性地从一条 warp 切换到另一条warp,以达到多处理器计算资源使用的最大化。warp 是线程调度的最小单元。
注意,块被划分成为 warp 的方式总是相同的; 每条 warp 包含连续的线程(一般用十六进制掩码 mask 的形式表示,每一个二进制位表示一个 thread,置位为 1 表示线程活跃,否则不活跃),线程索引从第一个warp 包含着的线程 0 开始递增。
线程块栅格 Grid
一个块可以包含的线程最大数量是有限的。然而,执行同一个kernel 的块可以合成一批线程块的栅格,因此通过单一 kernel 发送的请求的线程总数可以是非常巨大的。线程协作的减少会造成性能的损失,因为来自同一个栅格的不同线程块中的线程彼此之不间能通讯和同步。这个模式允许 kernel 用不同的并行能力有效地运行在各种设备上而不用再编译:一个设备可以序列地运行栅格的所有块
- 如果它有非常少的并行特性
- 如果它有很多的并行的特性
- 通常是二者的组合。
每个块是由它的块 ID 确定,块的 ID 是在栅格之内的块编号。根据块ID 可以帮助进行复杂寻址,一个应用程序可也以指定一个栅格作为任意大小的一个二维数组,并且通过一个 2- 组件索引替换来制定每个块。对于一个大小为 (Dx,Dy) 二维块,这个块的索引是(x,y),块的 ID 是(x + y Dx)。
内存或显存
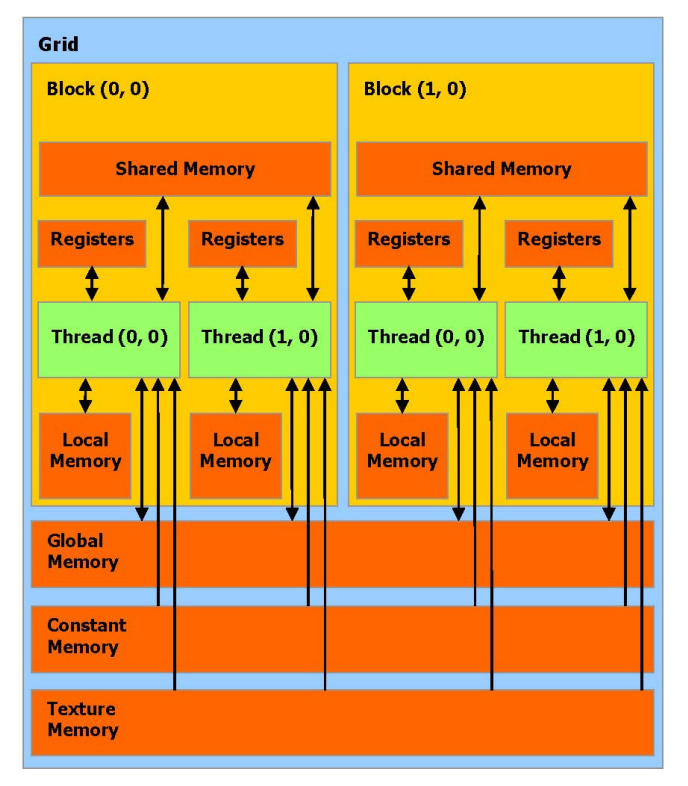
一条执行在设备上的线程,只允许通过如下的内存空间使用设备的 DRAM 和 On-Chip 内存,如图 2 所
示:
- 读写每条线程的寄存器,
- 读写每条线程的本地内存,
- 读写每个块的共享内存,
- 读写每个栅格的全局内存,
- 只读每个栅格的常量内存,
- 只读每个栅格的纹理内存。
全局,常量和纹理内存空间可以通过主机或者同一应用程序持续的通过kernel 调用来完成读取或写入。
全局,常量和纹理内存空间对不同内存的用法加以优化。纹理内存同样提供不同的寻址模式,也为一些
特殊的数据格式进行数据过滤。
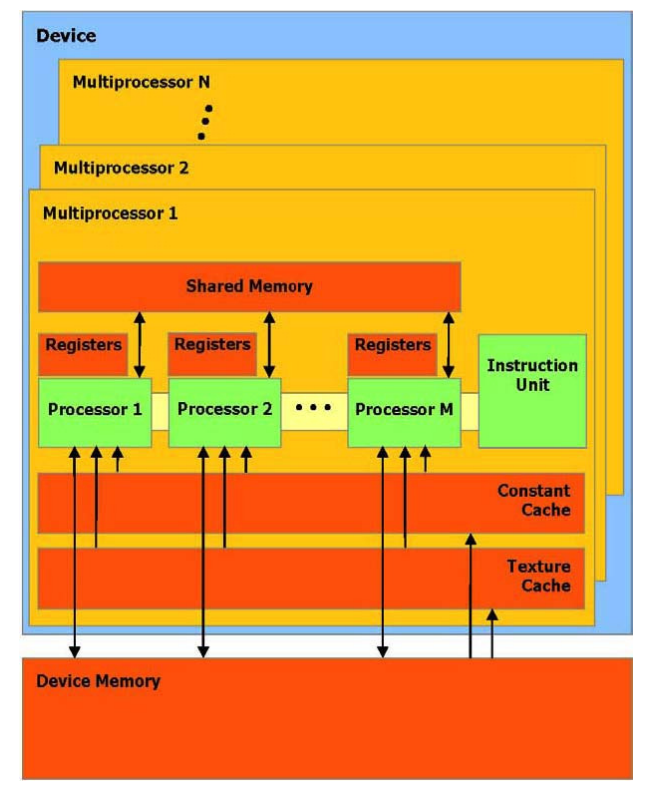
硬件实现
设备 (GPU) 可以被看作一组多处理器,如图 3 所示。每个多处理器使用单一指令,多数据架构 (SIMD) :在任何给定的时钟周期内,多处理器的每个处理器执行同一指令,但操作不同的数据。 每个多处理器使用四个以下类型的 on-chip(片上)内存:
- 每个处理器一组本地32 位寄存器,
- 并行数据缓存或共享内存,被所有处理器共享实现内存空间共享,
- 通过设备内存的一个只读区域,一个只读常量缓冲器被所有处理器共享,
- 通过设备内存的一个只读区域,一个只读纹理缓冲器被所有处理器共享,
本地和全局内存空间作为设备内存的读写区域,而不被缓冲。
每个多处理器通过纹理单元访问纹理缓冲器,它执行各种各样的寻址模式和数据过滤。