Thinking 4.1
思考并回答下面的问题:
-
内核在保存现场的时候是如何避免破坏通用寄存器的?
-
系统陷入内核调用后可以直接从当时的
$a0-$a3参数寄存器中得到用户调用 msyscall留下的信息吗? -
我们是怎么做到让
sys开头的函数“认为”我们提供了和用户调用msyscall时同样的参数的? -
内核处理系统调用的过程对
Trapframe做了哪些更改?这种修改对应的用户态的变化是什么?
答:
-
内核使用宏函数
SAVE_ALL来保存现场。由lab3相关介绍得知,SAVE_ALL仅仅使用了k0寄存器,且在使用前提前保存的k0。而k0、k1正是保留给操作系统使用的通用寄存器,故这样就避免了破坏通用寄存器。 -
可以。在由用户态到系统态的转变中并没有改变
$a0-$a3寄存器的值。但是不推荐这么做。(这个地方不太清楚,答疑的时候问下助教) -
用户态调用
msyscall时,传入的参数会被保存在$a0-$a3及堆栈中。当陷入内核时,$a0-$a3寄存器的值不会被破坏,而用户栈中的内容会被拷贝到内核栈中。所以sys开头的函数就“认为”我们提供了和用户调用msycall同样的参数。 -
根据实验代码,在处理过程中,
epc的值可能发生改变,同时将sys_*函数的返回值存入Trapframe中的v0寄存器中。这就保证了进入用户态时,用户程序能在正确的位置运行经过异常处理的程序,同时还能从v0寄存器中获得 系统调用的返回值。
Thinking 4.2
思考 envid2env 函数: 为什么 envid2env 中需要判断 e->env_id != envid
的情况?如果没有这步判断会发生什么情况?
答:
这实际上就是在判断转换后的 env结构体是不是对应 envid,如果不对应的话,无法对转换进行检验,可能产生未知的错误。因为这个 envid 可能还是没有分配对应进程的,也就是说还没有对应的结构体。
Thinking 4.3
思考下面的问题,并对这个问题谈谈你的理解:请回顾 kern/env.c 文件中 mkenvid() 函数的实现,该函数不会返回 ,请结合系统调用和 IPC 部分的实现与 envid2env() 函数的行为进行解释。
答:
由 return ((++i) << (1 + LOG2NENV)) | (e - envs); 这个语句可以发现,envid 是永远不可能为零的。在所有的系统调用中,如果 envid 为 ,都说明出现了错误。在 mkenvid 中,如果 envid 为 ,直接返回当前进程,这是用来标示父子进程的,事实上也保证 envid 不为零。
Thinking 4.4
关于 fork 函数的两个返回值,下面说法正确的是:
A、fork 在父进程中被调用两次,产生两个返回值
B、fork 在两个进程中分别被调用一次,产生两个不同的返回值
C、fork 只在父进程中被调用了一次,在两个进程中各产生一个返回值
D、fork 只在子进程中被调用了一次,在两个进程中各产生一个返回值
答:
C. fork 只在父进程中调用一次,产生子进程,从子进程和父进程中分别返回。其神奇之处在于:
它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值:
a) 在父进程中,fork 返回新创建子进程的进程 ID;
b) 在子进程中,fork 返回 ;
c) 如果出现错误,fork 返回一个负值。
Thinking 4.5
我们并不应该对所有的用户空间页都使用 duppage 进行映射。那么究竟哪些用户空间页应该映射,哪些不应该呢?请结合 kern/env.c 中 env_init 函数进行的页面映射、include/mmu.h 里的内存布局图以及本章的后续描述进行思考。
答:
最终需要被映射的页面只有 USTACKTOP 之下的部分。
UTOP 到 ULIM 之间存储的时和内核相关的信息。我们可以看到,在执行 env_alloc() 函数时,这一部分的映射关系直接从 boot_pgdir 拷贝到进程页表中,所以不需要映射。
在 UTOP 和 USTACKTOP 之间存放的是异常处理栈和无效内存,父子进程不需要共享这一部分。因为异常处理栈是进行异常处理用的地方,而剩余的空间一般情况下不会使用。
Thinking 4.6
在遍历地址空间存取页表项时你需要使用到 vpd 和 vpt 这两个指针,请参考 user/include/lib.h 中的相关定义,思考并回答这几个问题:
vpt和vpd的作用是什么?怎样使用它们?- 从实现的角度谈一下为什么进程能够通过这种方式来存取自身的页表?
- 它们是如何体现自映射设计的?
- 进程能够通过这种方式来修改自己的页表项吗?
答:
vpt 是获取页表,vpd是获取页目录,定义如下
#define vpt ((volatile Pte *)UVPT)
#define vpd ((volatile Pde *)(UVPT + (PDX(UVPT) << PGSHIFT)))
使用方法为 vpt[虚页号],vpt[虚页目录号]。
UVPT 和 UVPT + PDX(UVPT) << PGSHIFT 分别为 用户空间中页表的首地址和页目录的首地址。没有什么魔法,这就是虚拟地址的页表自映射。根据这些地址加上偏移量,也就可以得到对应的页表项和页目录项。
页目录基地址的计算方法体现了自映射设计。UVPT 起始的 4MB 的空间对应着页目录的第一个页目录项。同时由于 1MB 个页表项和 4GB 的地址空间是线性映射的,故这个地址应该是第 PDX(UVPT) 个页目录项,对应的地址偏移量为 PDX(UVPT) << PGSHIFT,所以页目录地址为 UVPT + PDX(UVPT) << PGSHIFT,这正好是页表自映射的另一种求解方法。
这也进一步说明 MOS 中允许在用户态下通过 UVPT 访问当前进程的页表和页目录。
不能。页表是内核态程序维护的,用户进程只能对页表项其进行访问,而不能对其进行修改。这么设计既保证了安全,又兼顾效率(减少系统调用),是巧妙的设计。
Thinking 4.7
在 do_tlb_mod 函数中,你可能注意到了一个向异常处理栈复制 Trapframe 运行现场的过程,请思考并回答这几个问题:
-
这里实现了一个支持类似于“异常重入”的机制,而在什么时候会出现这种“异常重入”?
-
内核为什么需要将异常的现场
Trapframe复制到用户空间?
答:
当用户程序写入了一个 COW 页,MOS就会进入页写入的异常处理程序,最终调用用户态的 pgfault 函数进行处理。但是,如果在 pgfault 函数中又写入了一个 COW 页,就会再次进入页写入的异常处理程序。然后再次调用 pgfault 函数 这样,就出现了所谓“异常重入”的现象。
但是,在 MOS 操作系统的代码中,不可能出现异常重入。在这个函数中,我们只是对异常处理栈进行了读写,而异常处理程序中的临时变量都保存在异常处理栈中,而异常处理栈对于父子进程而言各自独立,不会打上 COW 标志位。
虽然在这种情况下,“异常重入”显得并不必要,但是这并不意味着所有的情况下都不需要异常冲入。用户态的异常处理函数是用户程自行指定的,每个用户程序都可以通过 syscall_set_pgfault_handler() 注册一个自己的页写入异常处理函数。多用户操作系统难免会有用户的各种需求,如果由用户在自己注册的异常处理函数中写入全局变量,这就很有可能导致“异常重入”现象的发生。
综上所述,支持“中断重入”可以使使得操作系统据具有更好的可拓展性,满足更多用户的需求。
内核将异常现场的 Trapframe 复制到用户空间,是因为异常处理是在用户态进行的,而用户态只能访问用户空间的数据所以操作系统要将现场复制到用户空间。
实验难点
系统调用的处理流程
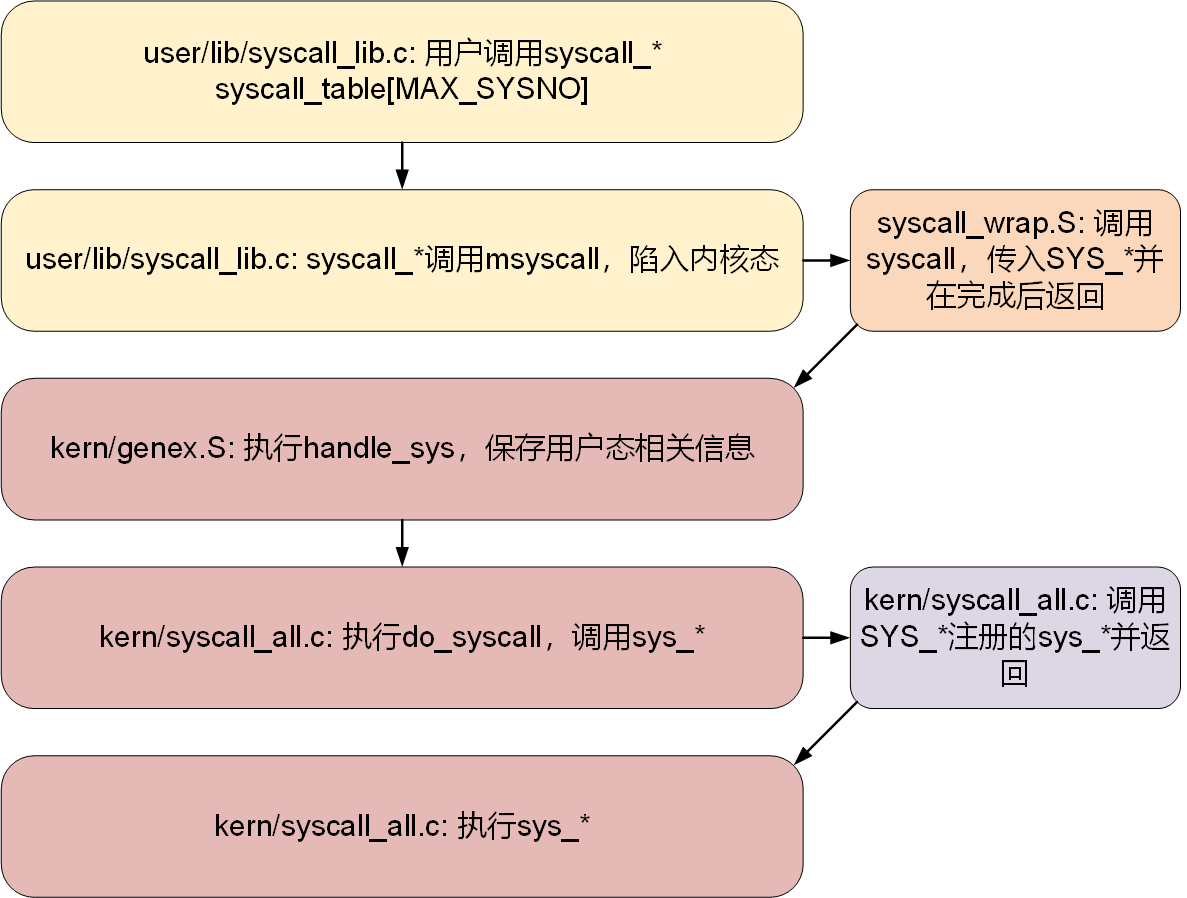
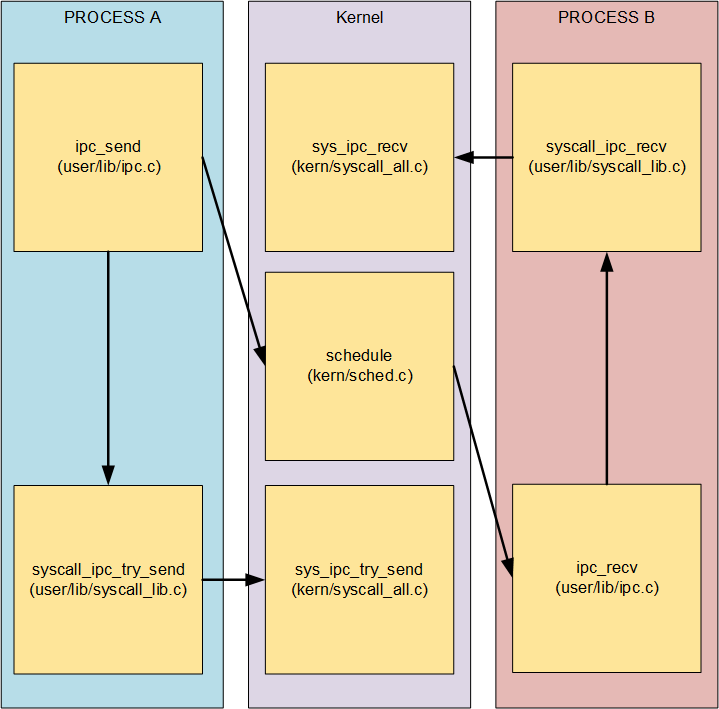
进程通信
操作系统fork
调用关系
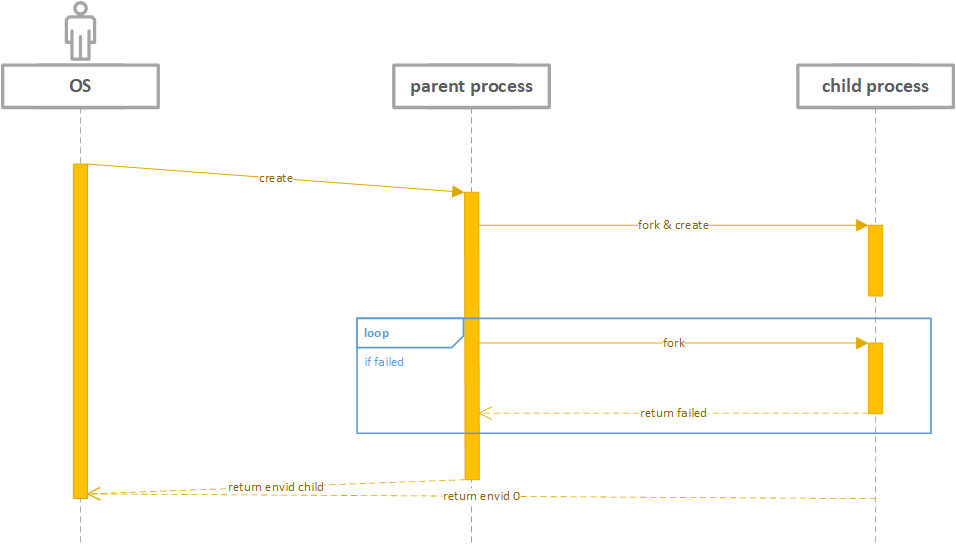
具体实现
用户调用 fork,fork 调用 syscall_set_tlb_mod_entry,设置自己的 TLB Mod 异常处理函数,调用 syscall_exofork,创建子进程,之后使用 duppage 复制地址空间并标记 COW,实现 copy on write,调用 syscall_set_tlb_mod_entry设置子进程的 TLB Mod 异常处理函数,调用syscall_set_env_status 修改进程控制块,此时子进程由 NOT Runnable 转为 Runnable,加入调度队列,择机正常运行;父子进程在 TLB Mod后执行 do_tlb_mod, 复制现场到 UXSTACKTOP 并将 EPC 设置为 curenv->env_user_tlb_mod_entry,再调用 cow_entry,按情况分配新页面,最后通过 syscall_set_trapframe 恢复现场,回到正常运行状态。
在4.9的时候出现了较大问题,是因为对 Lab3 相关知识点没吃透:
在 Lab3 中,我们在本实验里的寄存器状态保存的地方是
KSTACKTOP以下的一个sizeof(TrapFrame)
大小的区域中。
curenv->env_tf = *((struct Trapframe *)KSTACKTOP - 1)原题目:
/* Step 2: Copy the current Trapframe below 'KSTACKTOP' to the new env's 'env_tf'. */
/* Exercise 4.9: Your code here. (2/4) */
e->env_tf = *((struct Trapframe *)KSTACKTOP - 1); //structure最开始写成了 e->env_tf = curenv->env_tf,造成卡死。
心得
本次实验课下花费10小时,撰写实验报告花费时间10小时。实验很难,而且通过了测试离掌握知识还差距甚远,一定要强化理论知识训练。此外,即使理解了并不等于熟练使用,更不意味着实验和考试的时候拿到分数,因此还要加强练习,增加熟练度。让我们继续加油!
课上
lab4-1 exam
考察组 id,即组内(group)通信,基本按着提示给的步骤来就行。
lab4-1 extra
考察 broadcast,即对每一个子进程发送消息,也比较简单。
lab4-2 exam
考察 barrier,即通过阻塞使得一定数量的进程同步,没过。最大的问题在于在user/lib/ipc.c 中的两个函数:
void barrier_alloc(int n) {
syscall_barrier_alloc(n); //之前这里啥都没写!!!
}
void barrier_wait(void) {
syscall_barrier_wait(); //之前这里啥都没写!!!
}现在再来回顾一下涉及系统调用类题的解题流程:
- 功能函数添加流程是比较套路的,具体步骤为:
- 在
user/include/lib.h中添加功能函数的声明; - 在
user/lib/的对应文件中添加功能函数的定义,例如上文中的两个函数在user/lib/ipc.c中; - 在
user/lib/syscall_lib.c中添加对应的系统调用,如:syscall_barrier_alloc(int n)syscall_barrier_wait()
- 在
kern/syscall_all.c中实现内核态系统调用,注册中断函数。一个sys_*对应一个SYS_*。
- 在
- 最后反复检查各部分是否填写完善,最后才是各部分依次debug,切勿死磕一个部分,我这一次最大的问题就是在运行结果错误的时候没有把所有流程过一遍,只是简单地认为内核态错了,直到最后5分钟才发现问题,可惜已经来不及了,差了几秒没交上。实在遗憾。
完整代码:
/********* user/include/lib.c *********/
void barrier_alloc(int n);
void barrier_wait(void);
/*********** user/lib/ipc.c ***********/
void barrier_alloc(int n) {
syscall_barrier_alloc(n);
}
void barrier_wait(void) {
syscall_barrier_wait();
}
/******* user/lib/syscall_lib.c *******/
void syscall_barrier_alloc(int n) {
msyscall(SYS_barrier_alloc, n);
}
void syscall_barrier_wait(void) {
msyscall(SYS_barrier_wait);
}
/********* kern/syscall_all.c *********/
/* register iterrupt vector*/
void *syscall_table[MAX_SYSNO] = {
[SYS_barrier_alloc] = sys_barrier_alloc,
[SYS_barrier_wait] = sys_barrier_wait,
}
/* implement syscall funtion of kernel state*/
//globar variable
int barrier_size = 0;
int cnt = 0;
struct Env* total[128];
void recover() {
for (int i = 0; i < cnt; ++i) {
TAILQ_INSERT_TAIL((&env_sched_list), (total[i]), env_sched_link);
total[i]->env_status = ENV_RUNNABLE;
}
}
void sys_barrier_alloc(int n) {
threads_id = curenv->env_id;
barrier_size = n;
}
void sys_barrier_wait() {
if (cnt < barrier_size) {
if (curenv->env_status == ENV_RUNNABLE) {
curenv->env_status = ENV_NOT_RUNNABLE;
if (!TAILQ_EMPTY(&env_sched_list)) {
TAILQ_REMOVE((&env_sched_list), curenv, env_sched_link);
}
total[cnt++] = curenv;
}
}
if (cnt == barrier_size && barrier_size != 0) {
recover();
barrier_size = 0;
cnt = 0;
}
if (cnt < barrier_size) {
schedule(1); //another process
}
}
奇怪的是,并不需注意进程之间的父子关系,这一份代码就没有考虑,仍然可以通过评测,看来父子关系在测试数据中应该得到了保证。
lab4-2 extra
没过,一点都没看,之后重新开放后做了来填坑。
lab4 的第二次课上明显发挥失常,exam都没过。

