Thinking 3.1
请结合 MOS 中的页目录自映射应用解释代码中 e->env_pgdir[PDX(UVPT)] = PADDR(e->env_pgdir) | PTE_V 的含义。
e->env_pgdir[PDX(UVPT)]是将该进程的UVPT的页表偏移量取出,将对应位置的页目录设置为(e->env_pgdir) | PTE_V并开启只读,即将页目录所在页映射到自己
的虚拟地址,即完成页表自映射。
Thinking 3.2
elf_load_seg以函数指针的形式,接受外部自定义的回调函数 map_page。请你找到与之相关的 data 这一参数在此处的来源,并思考它的作用。没有这个参数可不可
以?为什么?
这里主要还是考察对回调函数的理解。data参数是传入的进程控制块指针。在load_icode函数中调用elf_load_seg函数,传入load_icode_mapper函数指针作为回调函数,同时传入data。在load_icode函数中data指向的是一个env类型的结构体,这个结构体包含了进程的各种信息,如进程id、进程状态、进程内存空间以及进程优先级等。map_page是一个回调函数,用于将ELF文件中的数据映射到进程内存空间中。如果没有这个参数,那么就无法将ELF文件中的数据映射到进程内存空间中,因此这个参数是必须的。
Thinking 3.3
结合 elf_load_seg 的参数和实现,考虑该函数需要处理哪些页面加载的情况。
源码
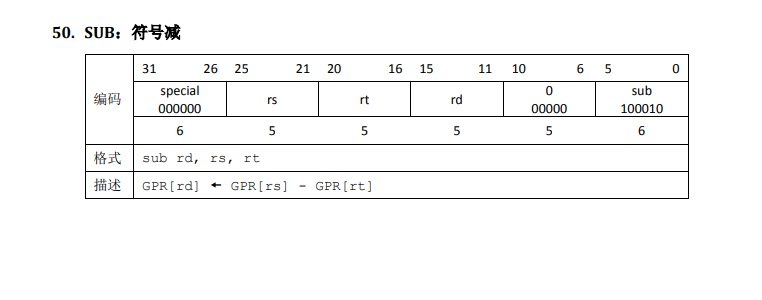
if (ph->p_flags & PF_W) {
perm |= PTE_D;
}
int r;
size_t i;
u_long offset = va - ROUNDDOWN(va, BY2PG);
if (offset != 0) {
if ((r = map_page(data, va, offset, perm, bin, MIN(bin_size, BY2PG - offset))) !=
1) {
return r;
}
}
/* Step 1: load all content of bin into memory. */
for (i = offset ? MIN(bin_size, BY2PG - offset) : 0; i < bin_size; i += BY2PG) {
if ((r = map_page(data, va + i, 0, perm, bin + i, MIN(bin_size - i, BY2PG))) != 0) {
return r;
}
}
/* Step 2: alloc pages to reach `sgsize` when `bin_size` < `sgsize`. */
while (i < sgsize) {
if ((r = map_page(data, va + i, 0, perm, NULL, MIN(bin_size - i, BY2PG))) != 0) {
return r;
}
i += BY2PG;
}
- 如果页面可写,就设置为脏的(Dirty)。
elf_load_seg函数会从ph中获取va该段需要被加载到的虚地址)、sgsize(该段在内存中的大小)、bin_size(该段在文件中的大小)和perm(该段被加载时的页面权限),并根据这些信息完成以下两个步骤:- 第一步 加载该段的所有数据(
bin)中的所有内容到内存(va)。 - 第二步 如果该段在文件中的内容的大小达不到为填入这段内容新分配的页面大小,即分配了新的页面但没能填满(如
.bss区域),那么余下的部分用0来填充。
- 第一步 加载该段的所有数据(
段内的内存布局可能较为复杂,需加载到的虚拟地址va、该段占据的内存
长度sg_size以及需要拷贝的数据长度bin_size都可能不是页对齐的。elf_load_seg会正确处理这些地址的页面偏移,对于每个需要加载的页面,用对齐后的地址va以及该页的其他信息。调用回调函数map_page,由回调函数完成单页的加载。这样的设计允许elf_load_seg只关心ELF段的结构,而不用处理与具体操作系统相关的页面加载过程。
Thinking 3.4
思考上面这一段话,并根据自己在 Lab2 中的理解,回答:
你认为这里的 env_tf.cp0_epc 存储的是物理地址还是虚拟地址?
虚拟地址。CPU从cp0_epc读取到返回的地址,然后返回造成异常的那条指令的地址。具体解释同lab2的第一个思考题。
Thinking 3.5
0-3号异常处理函数的具体实现位置:genex.S,
0号中断由以下代码单独实现:
24 NESTED(handle_int, TF_SIZE, zero)
25 mfc0 t0, CP0_CAUSE
26 mfc0 t2, CP0_STATUS
27 and t0, t2
28 andi t1, t0, STATUS_IM4
29 bnez t1, timer_irq
30 // TODO: handle other irqs
31 timer_irq:
32 sw zero, (KSEG1 | DEV_RTC_ADDRESS | DEV_RTC_INTERRUPT_ACK)
33 li a0, 0
34 j schedule
35 END(handle_int)
其余中断用汇编的.marco实现:
5 .macro BUILD_HANDLER exception handler
6 NESTED(handle_\exception, TF_SIZE, zero)
7 move a0, sp
8 jal \handler
9 j ret_from_exception
10 END(handle_\exception)
11 .endm
然后使用BUILD_HANDLER就实现了对应的异常处理函数:
37 BUILD_HANDLER tlb do_tlb_refill
38
39 #if !defined(LAB) || LAB >= 4
40 BUILD_HANDLER mod do_tlb_mod
41 BUILD_HANDLER sys do_syscall
42 #endif
43
44 BUILD_HANDLER reserved do_reserved
Thinking 3.6
阅读 init.c、kclock.S、env_asm.S 和 genex.S 这几个文件,并尝试说出
enable_irq 和 timer_irq 中每行汇编代码的作用。
timer_irq
32 sw zero, (KSEG1 | DEV_RTC_ADDRESS | DEV_RTC_INTERRUPT_ACK)
33 li a0, 0
34 j schedule
32:将0写入KSEG1 | DEV_RTC_ADDRESS | DEV_RTC_INTERRUPT_ACK所在的内存地址;
33:将a0寄存器置为0;
34:跳转到schedule函数。
enable_irq
16 li t0, (STATUS_CU0 | STATUS_IM4 | STATUS_IEc)
17 mtc0 t0, CP0_STATUS
18 jr ra
16:将(STATUS_CU0 | STATUS_IM4 | STATUS_IEc)写入t0寄存器;
17:将t0的值写入CP0_STATUS寄存器
18:返回上一级调用者函数
Thinking 3.7
阅读相关代码,思考操作系统是怎么根据时钟中断切换进程的。
kern/kclock.S中的kclock_init函数完成了时钟中断的初始化,该函数向KSEG1 | DEV_RTC_ADDRESS | DEV_RTC_HZ位置写入200,其中KSEG1 |DEV_RTC_ADDRESS是模拟器(GXemul)映射实时钟的位置。偏移量为DEV_RTC_HZ表示设置实时钟中断的频率,200表示1秒钟中断200次;如果写入0,表示关闭时钟中断。时钟中断对于GXemul来说绑定到了4号中断上。这里的中断号是仅针对不同种类的中断而言的,与异常无关。
init/init.c中的mips_init函数在完成初始化并创建进程后,需要调用kclock_init函数完成时钟中断的初始化,然后调用kern/env_asm.S中的enable_irq函数开启中断。
一旦实时钟中断产生,就会触发MIPS中断,从而系统将PC指向0x80000080,从而跳转到.text.exc_gen_entry代码段执行。对于实时钟引起的中断,通过.text.exc_gen_entry代码段的分发处理,最终会调用handle_int函数来处理实时钟中断。
handle_int中判断了Cause寄存器是不是对应的4号中断位引发的中断,如果是,则执行
中断服务函数timer_irq,跳转到schedule中执行。
每当时钟中断到来时,陷入内核态,调用schedule函数。schedule函数采用时间片轮转的算法。env中的优先级在这里起到了作用,这里规定其数值表示进程每次运行的时间片数量。寻找就绪状态进程不是简单遍历所有进程,而是用一个调度链表存储所有就绪(可运行)的进程,即一个进程在调度链表中当且仅当这个进程是就绪(ENV_RUNNABLE)状态的。当内核创建新进程时,将其插入调度链表的头部;在其不再就绪(被阻塞)或退出时,将其从调度链表中移除。调度函数schedule被调用时,当前正在运行的进程被存储在全局变量curenv中(在第一个进程被调度前为NULL),其剩余的时间片数量被存储在静态变量count中。进程切换包括以下几种情况:
- 尚未调度过任何进程(
curenv为空指针); - 当前进程已经用完了时间片;
- 当前进程不再就绪(如被阻塞或退出);
yield参数指定必须发生切换。
无论是否需要切换进程,都需要先将剩余时间片数量count 减去1。
当无需进行切换时,调用env_run函数,继续运行当前进程curenv;在发生切换的情况下,还需要先判断当前进程是否仍然就绪,如果是则应该先其移动到调度链表的尾部再进行调度。之后,选中调度链表头部的进程来调度运行,将剩余时间片数量设置为其优先级。
难点分析
本次实验的最大难点就是schedule函数,主要包括以下重要知识点:
- 函数上下文的理解和调用;
- 时间片轮转算法的理解和使用;
- 系统中断的产生和处理。
指导书再这几个方面花费大量笔墨进行讲解,我虽然进行了认真阅读,但难免还是有不理解的地方。通过结合这个函数的使用,我进一步了解了schedule函数的作用和功能,顺利地解决了bug。
我的bug主要有两个方面:
count自减的位置错误。我没有理解一旦进入调度函数就要将当前进程的可用时间片减去1。这条语句优先度是最高的,放在后面可能导致系统卡死。env_sched_list管理方式理解错误。schedule函数的调用方式保证了schedule函数使用env_sched_list的时候,进程控制块对应的进程一定都是RUNNABLE的。我之前尝试在e->env_status != ENV_RUNNABLE时候删除进程控制块e,导致了野指针的错误。
实验体会
本次实验花费8小时,撰写实验报告花费6小时,比lab2稍微轻松一些,这是因为lab2的学习增强了我对操作系统的虚拟页式管理系统的理解。
通过本次实验,我的以下几方面的能力得到了提升:
- 断点打印调试的能力。通过定义并复用宏,在各个测试点附近设置打印断点,可有效排查
bug。 - 对进程控制块的熟练程度。在多个函数中以不同方式设置进程控制块的不同信息,最终完成进程控制块的初始化。
- 对进程调度算法的理解和使用。虽然时间片轮转算法很简单,但是掌握理解它是学习和使用更复杂精巧进程调度算法的基础。
课上
exam
实现一个公平的调度算法,对于每个存在的用户,实现时间片的尽可能均匀分配。
- 非常简单,而且给了伪代码,直接照着写很快就能做出了。
- 前面的介绍和题目描述信息看一眼就好(
感觉也没有特别大的帮助,主要是看有无遗漏要点)。 - 命令行的使用一定要熟练,vim的快捷键要牢记,同时要学会快速调试。
代码:
#include <env.h>
#include <pmap.h>
#include <printk.h>
/* Overview:
* Implement a round-robin scheduling to select a runnable env and schedule it using 'env_run'.
*
* Post-Condition:
* If 'yield' is set (non-zero), 'curenv' should not be scheduled again unless it is the only
* runnable env.
*
* Hints:
* 1. The variable 'count' used for counting slices should be defined as 'static'.
* 2. Use variable 'env_sched_list', which contains and only contains all runnable envs.
* 3. You shouldn't use any 'return' statement because this function is 'noreturn'.
*/
void schedule(int yield) {
static int count = 0; // remaining time slices of current env
struct Env *e = curenv;
static int user_time[5];
/* We always decrease the 'count' by 1.
*
* If 'yield' is set, or 'count' has been decreased to 0, or 'e' (previous 'curenv') is
* 'NULL', or 'e' is not runnable, then we pick up a new env from 'env_sched_list' (list of
* all runnable envs), set 'count' to its priority, and schedule it with 'env_run'. **Panic
* if that list is empty**.
*
* (Note that if 'e' is still a runnable env, we should move it to the tail of
* 'env_sched_list' before picking up another env from its head, or we will schedule the
* head env repeatedly.)
*
* Otherwise, we simply schedule 'e' again.
*
* You may want to use macros below:
* 'TAILQ_FIRST', 'TAILQ_REMOVE', 'TAILQ_INSERT_TAIL'
*/
/* Exercise 3.12: Your code here. */
int avail_user[5] = {0, 0, 0, 0, 0};
// int user_len = 0;
struct Env *tmp_env;
TAILQ_FOREACH(tmp_env,(&env_sched_list), env_sched_link) {
if (tmp_env != NULL) {
avail_user[tmp_env->env_user]++;
}
}
//count = count - 1;//adjust
if (yield || count == 0 || e == NULL || e->env_status != ENV_RUNNABLE) {
if (e != NULL) {
if (e->env_status != ENV_RUNNABLE) {
//TAILQ_REMOVE((&env_sched_list), e, env_sched_link);
} else {
TAILQ_REMOVE((&env_sched_list), e, env_sched_link);
TAILQ_INSERT_TAIL((&env_sched_list), e, env_sched_link);
user_time[e->env_user] += e->env_pri;
}
}
if (TAILQ_EMPTY((&env_sched_list))) {
panic("env_sched_list is empty!");
//return;
}
int min_time = -1;
int id = -1;
for (int i = 0; i < 5; ++i) {
if (avail_user[i] != 0) {
if (min_time == -1) {
id = i;
min_time = user_time[i];
} else {
if (min_time > user_time[i]) {
id = i;
min_time = user_time[i];
}
}
}
}
TAILQ_FOREACH(tmp_env, (&env_sched_list), env_sched_link) {
if (tmp_env != NULL && tmp_env->env_user == id) {
break;
}
}
count = tmp_env->env_pri;
e = tmp_env;
}
count--;
env_run(e);
}
extra
爬了,又没过,连续两次不过extra了,好伤心。
和去年的考察形式一模一样,还是异常处理。去年是AdEL,今年是Ov。
题目大致内容如下:
- 完成对地址错误中的
Ov错误进行处理,在抛出这个异常后编写完成 kern/traps.c 中的异常分发和kern/genex.S 中的处理异常的汇编代码,使其能完成题目要求的对该类异常的正确处理。主要处理add,sub,addi三个指令。add转化为addusub转化为subuaddi将epc改为epc + 4,将rt寄存器的值设置为rs / 2 + imm / 2
- 注意看清各指令的 opcode 码。


没做出来的原因有三个:
- 计组的知识忘差不多了,对异常协处理寄存器
cp0完全不熟悉,R I J型指令格式也不熟悉了。 - 位运算不熟悉,考试时候紧张不知道怎么取一个数的特定几位。
- 页式虚拟内存管理不熟悉。不会根据虚拟地址查找对应的物理地址。
代码
kern/traps.c
void do_ov(struct Trapframe *tf) {
//save
unsigned long addr = tf->cp0_epc; // va
Pde *env_pgdir = curenv->env_pgdir + PDX(addr);
Pte *table_1 = (Pte *)KADDR(PTE_ADDR(*env_pgdir)) + PTX(addr); //由于这个地址一定有效(已经被执行),所以不需要有效性检验(即&PTE_V)
u_int* vaddr = (u_int*)(KADDR(PTE_ADDR(*table_1)) + (addr & 0xFFF)); //do not use pgdir_walk | kva kseg0 //强制转化为指向四个字节的指针
u_int item = *(vaddr);
if ((item >> 26) == 0 && (item & ((1 << 6) - 1)) == (u_int)32) { //(u_int)强制类型转换其实不需要,因为是正数,首位为零,但这样可读性好
*(vaddr) = (item & ~((1 << 6) - 1)) | (u_int) 33; //可以用十六进制表示会更好
printk("add ov handled\n");
} else if ((item >> 26) == 0 && (item & ((1 << 6) - 1)) == (u_int)34) {
*(vaddr) = (item & ~((1 << 6) - 1)) | (u_int) 35;
printk("sub ov handled\n");
} else if ((item >> 26) == (u_int)8 ) {
tf->regs[(item >> 16) & ((1 << 5 - 1))] = ((item & ((1 << 16) - 1)) >> 1) + (tf->regs[(item >> 21) & ((1 << 5) - 1)] >> 1);
tf->cp0_epc = tf->cp0_epc + 4;
printk("addi ov handled\n");
}
curenv->env_ov_cnt++;
}
或者直接使用pgdir_walk
pgdir_walk(curenv->env_pgdir, addr, 0, &table_1);
//避免重复造轮子
- 获取一个数的低
k位:num & ((1 << k) - 1) - 获取一个数的最高位到
k + 1位:num & ~((1 << k) - 1) - 判断
A的所有位是不是包含BA & B == B

